https://arxiv.org/abs/2508.15734
Abstract: The transformative power of AI is undeniable - but as user adoption accelerates, so does the need to understand and mitigate the environmental impact of AI serving. However, no studies have measured AI serving environmental metrics in a production environment. This paper addresses this gap by proposing and executing a comprehensive methodology for measuring the energy usage, carbon emissions, and water consumption of AI inference workloads in a large-scale, AI production environment. Our approach accounts for the full stack of AI serving infrastructure - including active AI accelerator power, host system energy, idle machine capacity, and data center energy overhead. Through detailed instrumentation of Google’s AI infrastructure for serving the Gemini AI assistant, we find the median Gemini Apps text prompt consumes 0.24 Wh of energy - a figure substantially lower than many public estimates. We also show that Google’s software efficiency efforts and clean energy procurement have driven a 33x reduction in energy consumption and a 44x reduction in carbon footprint for the median Gemini Apps text prompt over one year. We identify that the median Gemini Apps text prompt uses less energy than watching nine seconds of television (0.24 Wh) and consumes the equivalent of five drops of water (0.26 mL). While these impacts are low compared to other daily activities, reducing the environmental impact of AI serving continues to warrant important attention. Towards this objective, we propose that a comprehensive measurement of AI serving environmental metrics is critical for accurately comparing models, and to properly incentivize efficiency gains across the full AI serving stack.
This only came out a couple of days ago but has already gotten a lot of attention from the wider press and public.
I’m going to talk about this in Zone of Controversy below after the regular paper review, but my short opinion is: good paper, and Google deserves credit for this new level of transparency, but there are what look like very intentional gaps, and the whole thing suffers from marketing spin and the distrust that Google (and other AI companies) have earned in the last few years.
First up, this paper does a nice job of laying out previous work in this area, pointing out how widely varying the estimates are, and making a good argument that it’s mostly because they are measuring different things. The authors then describe the measurement boundary they will use (described as the Comprehensive Approach) and why it should probably be used for future work. The cynic in me immediately jumped to https://xkcd.com/927/, but honestly I think the boundary proposed makes sense:
- Energy consumption includes:
- AI accelerators (TPUs/GPUs)
- Host machine CPU and DRAM
- Any idle/overprovisioned hardware running to provide better reliability or latency
- The PUE of the enclosing data centre.
- Energy consumption does not include:
- External (to the DC) networking
- End user devices
- LLM training and data storage - that’s for another paper.
I’m glad that idle hardware power consumption is being included and I think it’s fair to treat training separately to inference.
What were the results? First up, energy:

So we can see that ~60% of energy consumption goes to AI accelerators, with ~25% for the host CPU and DRAM.
Next, CO2e emissions. The authors make the decision to use an global, annual, market-based (MB) emissions factor (EF) average. This allows discounting the EF of a local grid with a lower EF from a remote grid where Google has made some carbon free energy (CFE) procurement. This is opposed to location-based(LB) where you need to use the EF of the local grid. So we have one EF figure for the whole globe, for the whole year which is not great.
Anyway, we end up with a figure of 0.03gCO2e/prompt, with ~66% of that for scope-2 MB emissions, and 33% for scope-1 and scope-3.
Water consumption is then calculated based on another global average, this time for water usage effectiveness (WUE) was 1.15 L/kWh in 2024, which gives the result of 0.26mL/prompt.
Finally we come to the section describing efficiency gains between May 2024 and May 2025 and the headline number really is very impressive:
a 44x reduction in the total emissions per median Gemini Apps text prompt over 12 months
That 44x comes from:
- 33x reduction in per-prompt energy (23x reduction from model improvements, 1.4x from improved machine utilisation)
- 1.4x reduction in MB emissions-factor from running in lower EF locations and CFE procurements.
- 36x reduction in scope 1+3 emissions by lower machine-hours per prompt (ie: lower latency) and the associated reduction in amortisation per prompt.
Zone of Controversy
So what are some of the concerns and problems people (including me) have?
Some things I read around this paper:
- This MIT Technology Review article: In a first, Google has released data on how much energy an AI prompt uses that was released at approximately the same time as the paper.
- Ketan Joshi’s response: Big tech’s selective disclosure masks AI’s real climate impact
- Hannah Ritchie’s updated: What’s the carbon footprint of using ChatGPT or Gemini? [August 2025 update]
From most to least fair criticisms IMO:
Why are we only getting a median value?
Why is this paper only publishing median values for energy/CO2e/water per prompt? The author’s description of how they calculated the median sure makes it sound like they could have provided other percentiles, distributions etc.
And this isn’t just about the median hiding something about the underlying distribution; a single prompt might be cheap, but maybe there are huge numbers of prompts making the sum huge, especially when you realise that AI is being bolted onto every product whether people necessarily want it or not, AND that reasoning models generate way more internal prompts than the original user is responsible for.
It’s hard not to think Google is holding back data because of fear of negative reactions.
Why are they using market-based rather than location-based emissions factors?
In another very recent paper. Google did emissions calculations using both market-based and location-based emissions. So when they don’t do it here, and don’t meaningfully address the omission, it looks like intentional obfuscation.
Just because these numbers look small doesn’t mean that growing AI usage and infrastructure isn’t causing environmental problems.
As Hannah Ritchie puts it
The fact that AI chatbots are a small part of most individual footprints does not mean I don’t think AI and data centres as a whole are not a problem for energy use and carbon emissions. I think that, particularly at a local level, managing load growth will be a challenge.
And Ketan has more words than I can quote but here’s a sample
A single person querying a chatbot isn’t as energy intensive as heating food, or moving in a car. But the broader implementation of generative systems (text-spam ‘reasoning’, images, videos, enforced demand through design tricks etc) is energy hungry in aggregate, and it’s getting worse every day.
My first reaction was that this is a bit unfair and is conflating larger problems with AI with a paper that’s only trying to calculate per-prompt emissions and resource consumption. But to some extent it’s invited by the title of the paper, sentences like “0.24 Wh represents less energy than watching TV for 9 seconds. The water use of 0.26 mL equals five drops of water”, and the dodgy methodological choices already mentioned.
This is just inference costs, why didn’t they include training costs which will be way bigger?
Two things
- I don’t think it’s fair to criticise a paper for not being a different paper.
- Based on previously publications, training energy costs (and hence emissions and water consumption) is likely to be less than inference costs over the lifetime of a model. This (admittedly old) paper claims about a 40/60 split for training/inference, and this newer paper uses a similar number.
This is only for text, not images or video
Again, a fair criticism of the company. Google should absolutely be publishing datasets for all these modes, but that’s not the fault of this paper.
Notes
- 0.24Wh/0.03 gCO2e/0.15ml water for a median Gemini Apps query. Compare to Mistral): 1.14gCO2e/50ml water
- Functional unit of study: one serving AI computer (host) deployed in the data center, which includes one or more AI accelerator trays (containing AI accelerators) connected to one host tray
- New proposed broad measurement boundary (cf: electricity_intensity_of_internet_data_transmission): includes energy for
- TPUs/GPUs
- host machine’s CPU and DRAM
- overprovisioned machines for reliability and latency
- DC PUE
- does not include
- external (to the DC) networking
- end user devices
- LLM training and data storage - that’s for another paper.
- Nice job of going through previous estimate approaches and highlighting the very wide range of results and the weaknesses in each approach.
- These numbers “suggests that a scaling of 1.72 would need to be applied to active AI accelerator energy consumption to include the energy consumed in a production serving environment”
- Using market-based (MB) emissions factor (EF) which allows discounting the EF of a local grid with a lower EF from a remote grid if we paid for it. This is opposed to location-based(LB) where you need to use the EF of the local grid. It’s actually worse than just MB: “We apply the previous calendar-year’s average emissions factors to account for the fact that these metrics are published once per year” - a whole year global average is extremely crude.
- BUT, they do include lifecycle emissions (scope 3) as calculated in An_Introduction_to_Life-Cycle_Emissions which is not common.
- Water consumption is calculated based on another global average, this time for water usage effectiveness (WUE) was 1.15 L/kWh in 2024.
- What about improvements?
- “a 44x Measuring the environmental impact of delivering AI at Google Scale 8 reduction in the total emissions per median Gemini Apps text prompt over 12 months”
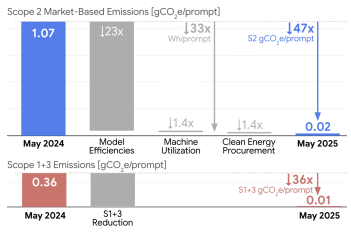
- 33x reduction in per-prompt energy (23x reduction from model improvements, 1.4x from improved machine utilisation)
- 1.4x reduction in MB emissions-factor from CFE procurements and location changes.
- 36x reduction in scope 1+3 emissions by lower machine-hours per prompt (lower latency) and associated reduction in amortisation.
