This is a followup to two previous posts on the theory of data center load flexibility:
- Tyler Noriss’ Rethinking Load Growth
- MIT’s Flexible Data Centers and the Grid: Lower Costs, Higher Emissions?
There are now three publicised real-world implementations that I know of. Only three (and two of those with Google), but it seems likely that the biggest hurdle left for wider deployment is to build confidence with utilities and not technically feasibility.
Of course the future of the AI boom is far from certain. Public sentiment seems to be shifting and reality may finally catching up with some of the hype. But if that happens and demand falls short of the astronomical predictions, having smarter DC load orchestration is still a win that allows optimising workloads against cost/emissions/capacity.
Emerald AI/Oracle/NVIDIA in Phoenix, Arizona
Emerald AI have written about a field demonstration using their proprietary software in collaboration with Oracle and NVIDIA. This is part of EPRIs DCFlex initiative.
Note that despite the format this is very much a self-published white paper and not peer-reviewed. That said, it does a good job laying out the methodology and results
To quote the authors
Our central hypothesis is that GPU driven AI workloads contain enough operational flexibility–when smartly orchestrated–to participate in demand response and grid stabilization programs
The setup:
- The “cluster” being tested is teeny-tiny, only 256-GPUs, and < 100kW. So one or two racks.
- Jobs are classified via tags into different flexibility tiers based on their tolerance for runtime or throughput deviations.
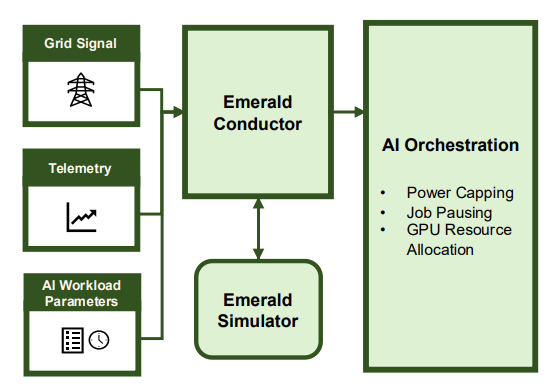
- It’s a software-only solution. Emerald software
- takes grid signals, job tags and job telemetry as inputs
- uses this to predict the power-performance behaviour of AI jobs
- recommends an orchestration strategy to meet both AI SLAs and power grid response commitments
- implements that strategy throw a combination of controls knobs
- power capping via dynamic voltage frequency scaling (DVFS)
- job pausing
- changing the number GPUs allocated per job
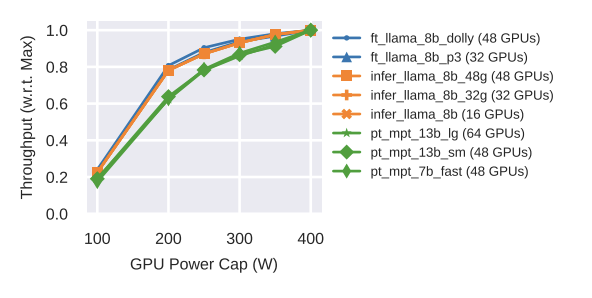
- Four representative workload ensembles were selected, with varying proportions of training, inference, and fine-tuning jobs.
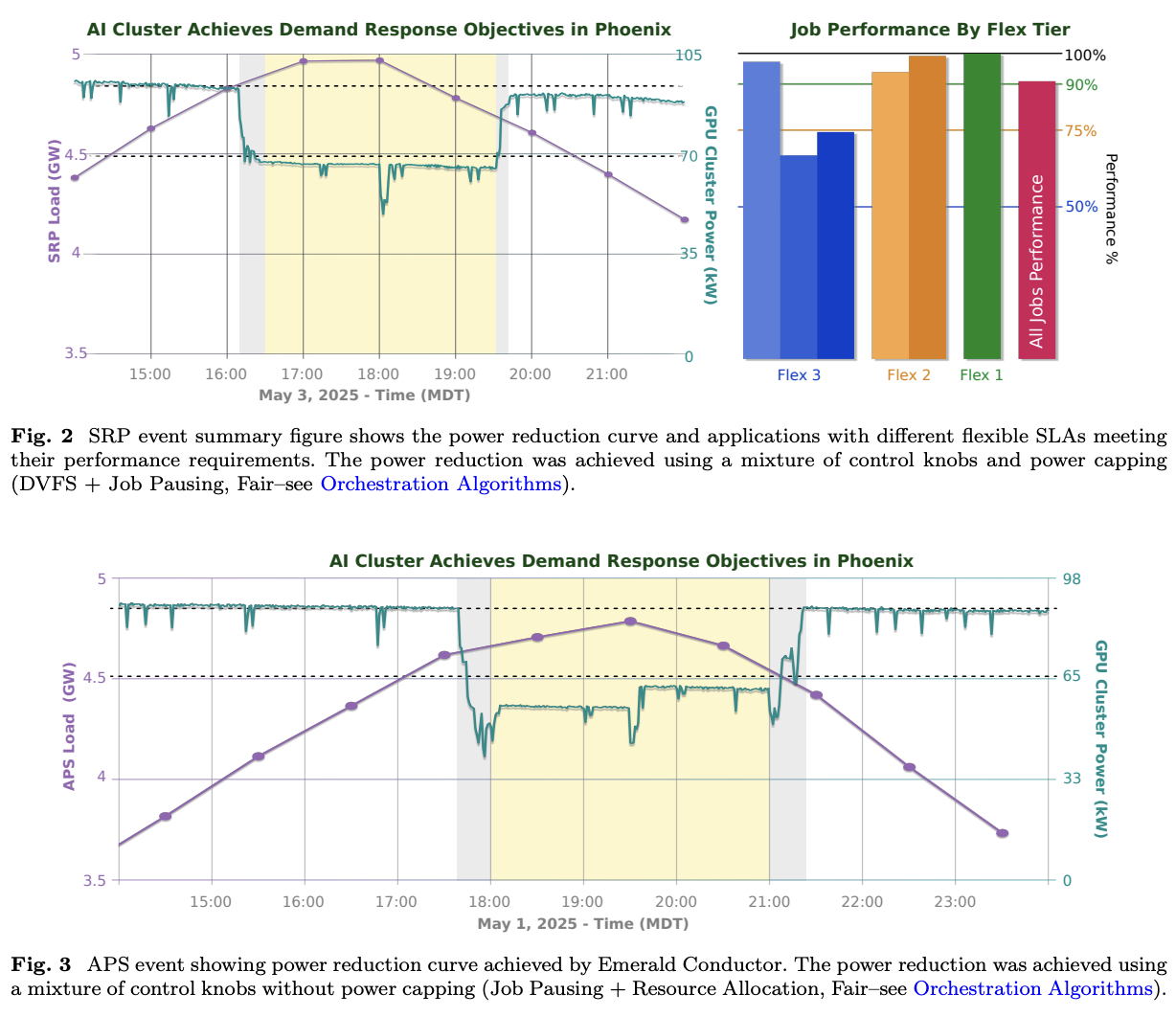
The system responded to two real-world events, in each case reducing load by 25% for 3hrs (WRT to average base load), with a 15m ramp/up down, without violating SLAs.
They also ran some simulations that went well, but I find these less interesting from a confidence-building point of view.
Google in Indiana and North Carolina
First up, theres a demonstration site in Lenoir where Google is coordinating with the EPRI. It’s part of the same DCFLex program as the above Emerald AI demonstration, and based on their progress I would hope something is happening/will happen soon, but I can’t find anything published.
Second, Google has signed a utility agreement for a demand-response project that “centers on the tech giant’s $2 billion data center in Fort Wayne, Indiana, which started operations late last year but expects to ramp up its power needs over time”.
There’s also very little info on this one. The official Google post is pretty thin, but this Canary Media post pulls together a bit more colour from Tyler Norris (of rethinking_load_growth fame) and Michael Terrell (from Google).
So watch this space I guess.
Notes
- Turning AI Data Centers into Grid-Interactive Assets: Results from a Field Demonstration in Phoenix, Arizona
- 256-GPU cluster, in Phoenix, Arizona - < 100kW - teeny tiny, one rack?
- Oracle, Nvidia, Emerald AI, coordinated via EPRI DCFlex initiative
- Software-only solution. Just using workload orchestration, 25% reduction in cluster power usage for three hours during peak grid events while maintaining AI SLAa.
- “Our central hypothesis is that GPUdriven AI workloads contain enough operational flexibility–when smartly orchestrated–to participate in demand response and grid stabilization programs”
- “Although utilities offer financial incentives for power flexibility, other adoption costs–such as impacts on workload performance and delays in deploying new data centers–can limit participation…Utilities and system operators can further prioritize flexible AI data centers for accelerated interconnection”
- Emerald Conductor software turns AI cluster into a grid-responsive asset
- Emerald conductor: connects to AI workload manager (Databricks MosaicML) and grid signals.
- Emerald simulator: predicts the power-performance behaviour of AI jobs. Recommends an orchestration strategy meet both AI SLAs and power grid response commitments.
- Not shown in diagram: workload tagging schema classifies jobs into flexibility tiers based on user tolerance for runtime or throughput deviations. Allows greater flexibility in meeting SLAs.
- Four flexibility classes after discussing with industry partners (Oracle and Nvidia?)
- 0: no performance reduction allowed
- 1: up to 10% performance (average throughput) reduction allowed over a 3-6 hour period - just training?
- 2: up to 25% allowed
- 3: Up to 50% allowed
- Four representative workload ensembles were selected, with varying proportions of training, inference, and fine-tuning jobs.
- Control knobs
- Nvidia power capping: dynamic voltage frequency scaling (DVFS) to reduce power. Probably the simplest action, requires no scheduling changes, checkpointing etc.
- Job pausing
- Changing allocated GPUs for jobs
- Reacted to two real events, reducing load by 25% each time WRT to average base load over 3hrs. 15m ramp/up down window.
- All jobs completed within SLA window.
- Also simulated 2020 CAISO outage
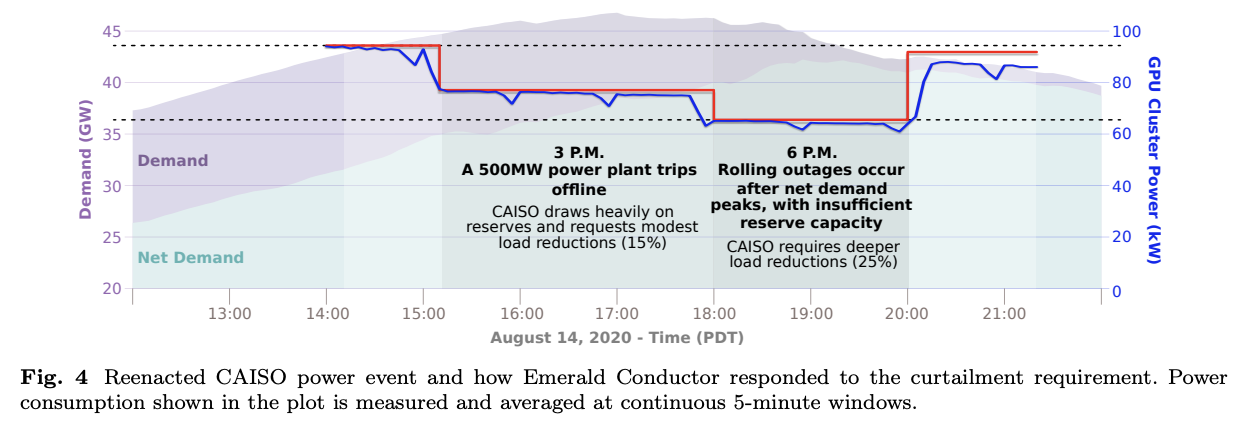
- The system delivered both reductions smoothly, matching the desired power profile
- Maintained SLAs
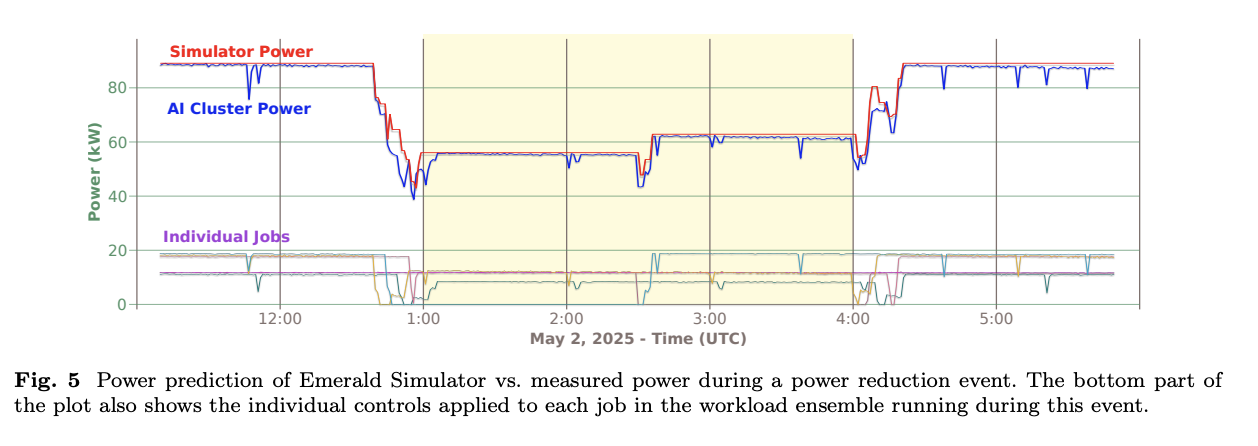
- Simulator accuracy
- Across control intervals in our experiments, the model achieved 4.52% root-mean-square error (RMSE) in power predictions, relative to average experiment power (Fig. 5).
- Individual job behaviors were well enough to stay within SLAs.
- A bunch of implementation details not that interesting except like all scheduling choices there is a tradeoff between greediness and fairness.
- https://blog.google/inside-google/infrastructure/how-were-making-data-centers-more-flexible-to-benefit-power-grids/
- Two new utility agreements with Indiana Michigan Power (I&M) and Tennessee Valley Authority (TVA)
- https://www.canarymedia.com/articles/utilities/google-ai-data-center-flexibility-help-grid
- Has a bit more info including quotes from Tyler Norris and Michael Terrell (from Google)
- “A Department of Energy report last year “identified no examples of grid-aware flexible operation at data centers” in the U.S., with one exception — Google.”
- data centers “north of Nashville and in North Alabama
- centers on the tech giant’s $2 billion data center in Fort Wayne, Indiana, which started operations late last year but expects to ramp up its power needs over time
- Google will commit both to restraining its use of power at its Fort Wayne data center during critical hours and to transferring credits for a portion of carbon-free energy it has contracted for in the region to I&M to help it meet its capacity requirements.