https://arxiv.org/pdf/2505.06371
Abstract: As the adoption of Generative AI in real-world services grow explosively, energy has emerged as a critical bottleneck resource. However, energy remains a metric that is often overlooked, under-explored, or poorly understood in the context of building ML systems. We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments, and the corresponding ML.ENERGY Leaderboard, which have served as a valuable resource for those hoping to understand and optimize the energy consumption of their generative AI services. In this paper, we explain four key design principles for benchmarking ML energy we have acquired over time, and then describe how they are implemented in the ML.ENERGY Benchmark. We then highlight results from the latest iteration of the benchmark, including energy measurements of 40 widely used model architectures across 6 different tasks, case studies of how ML design choices impact energy consumption, and how automated optimization recommendations can lead to significant (sometimes more than 40%) energy savings without changing what is being computed by the model. The ML.ENERGY Benchmark is open-source and can be easily extended to various customized models and application scenarios.
I read this as part of nosing around https://github.com/ml-energy/zeus. I mostly wanted to get a feel for the project so didn’t go deep into the details, but a few things were interesting:
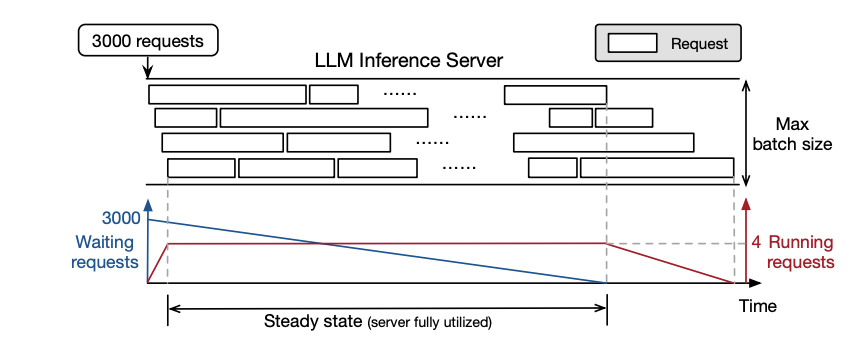
- Diffusion models and LLMs have different runtime characteristics so you need to measure their energy consumption differently. Specifically, LLMs do per-request iteration within a batch of requests which means that start and finish times within the batch are not aligned. To compensate for this, the benchmark software only measures during “steady state”
-
You can’t just use a GPUs Thermal Design Power (TDP) to estimate power usage, you actually have to measure it. GPUs don’t normally run at full power and different model types will have different GPU utilisation characteristics. For example, compared to diffusion models, LLMs display relatively low compute-intensity with the GPU computation throughput being bottlenecked by VRAM bandwidth and a low power draw.
-
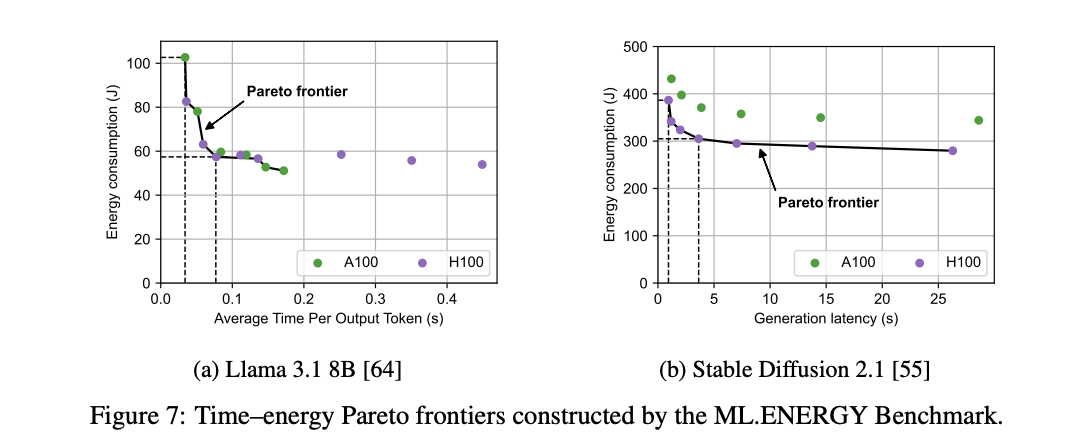
It’s possible to get outsized energy savings for relatively small sacrifices in latency
Notes
- measuring inference energy consumption
- provides automated energy optimization recommendations for generative AI model deployment
- just looks at GPUs because they consume 50-70% of power in a DC, fairly standardized (compared to CPUs, DRAM, system configuration), have accurate software-based energy measurement
- vLLM on NVIDIA H100s
- report energy consumption at the granularity of a single, whole generation response to a request (e.g., entire chat response, image, video)
- Benchmark
- Zeusused to measures time and energy consumption during benchmarking.
- Uses these time/energy results to pick an optimal energy config based on user-provided latency requirements.
- Need to figure out per-request energy usage when systems typically batch together requests
- Diffusion models: , where the batch consists of image or video generation requests.
- LLM text generation:
- Because of iterative nature of request processing, beginning and end of all requests are generally not aligned. So we wait for measure steady-state of system - the period during which the batch size is saturated at the server’s maximum configured batch size.
- , ie: the average energy consumption per token during the steady state multiplied by the average number of output tokens
- Automated optimization recommendations: “construction of the Pareto frontier of energy vs. time, which is a collection of configurations where there is no other configuration that leads to both lower energy and lower time”
- Results
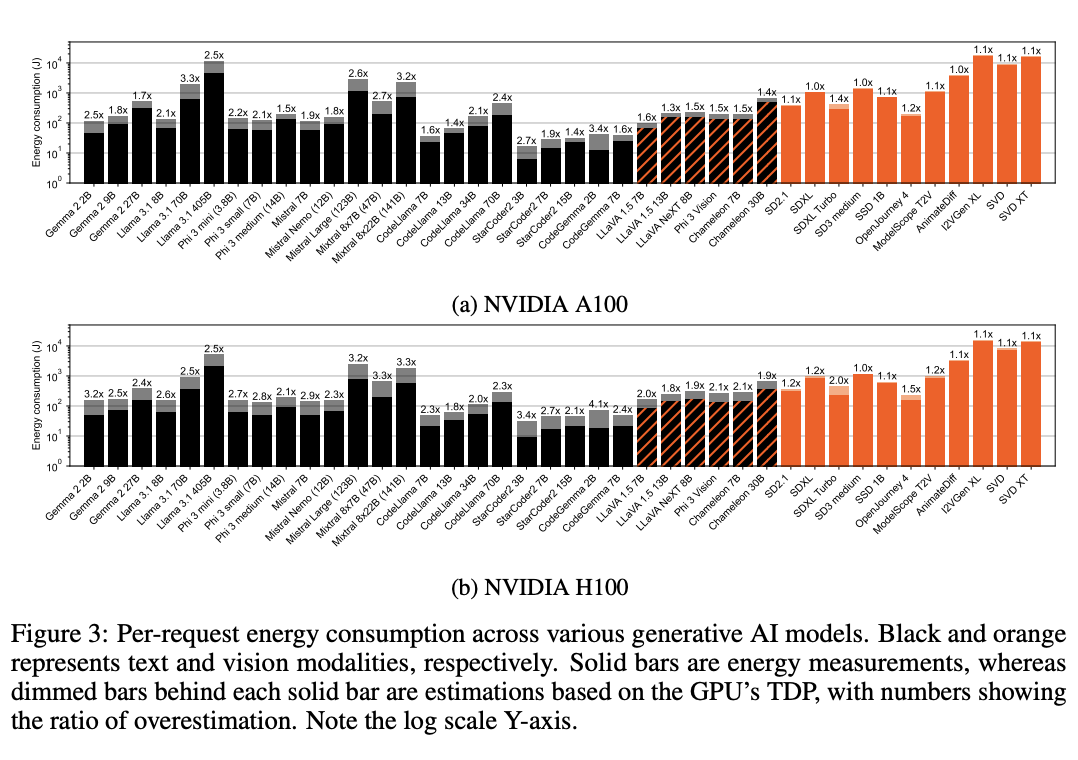
- Note how the dimmed bars estimate energy consumption based on the GPU’s Thermal Design Power (TDP) instead of measuring the real GPU power consumption, which is a common practice and is nearly always an overestimation since it is rare for a GPU – or any computing device – to draw its maximum power at every moment in time.
- LLMs: big variation even in models of similar size due to higher verbosity (output length) for some models.
- LLM decoding is characterized by low compute-intensity, meaning that the number of arithmetic operations (e.g., multiplication and addition) per byte of memory loaded is low compared to diffusion models. This leads to the GPU’s computation throughput being bottlenecked by VRAM bandwidth and results in the GPU’s computation units being underutilized, leading to low power draw.